
En esta edición me gustaría agradecer a todos los que han pasado a leer el blog, espero que todos ustedes se encuentren bien. Este día quiero compartirles como empece en el mundo de la gestión de las configuraciones, que he aprendido, y les compartiré algo de código de infraestructura.
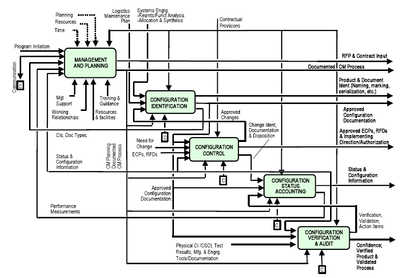
La gestión de configuraciones, o configuration management en inglés, consiste en procesos para establecer y mantener la consistencia de los atributos de un sistema considerando requisitos, diseño, y operación. Es decir, se gestiona la información relacionada a todo el ciclo de vida de los sistemas o servicios.
Aquí ya entramos en temas como el Ciclo de Vida de Desarrollo de Software ó SDLC por sus siglas en inglés, y también en temas de administración de servicios de TI. Entrar en estos terrenos me trajo muchas dudas: de pronto estaba metido en proyectos basados en SDLC de tipo cascada al mismo tiempo que en otros proyectos de tipo ágil y demás modelos operativos.
La gestión de configuraciones incluye el como administramos nuestro propio sistema, escritorio, hasta un servidor con GNU/Linux o grupos de servidores. Antes de poder administrar el sistema de alguien más debemos empezar por el nuestro.
En la filosofia Unix todo es un archivo, entonces la gestión de las configuraciones en Linux se refiere a la correcta administración de archivos :). Uno de los objetivos es mantener la consistencia en las configuraciones, siempre considerando mejorar la operación de servicios digitales. Así entré en el mundo de las herramientas de gestión de configuraciones open source. Como les comente antes, empece con CFEngine, después conocí Puppet, seguido de Chef, Ansible y SaltStack, los que he usado para gestionar las configuraciones de sistemas operativos basados en GNU/Linux.
La infraestructura como código se refiere a la forma de administrar la infraestructura donde se usa un modelo declarativo para describir las configuraciones de los diferentes recursos. Puede ser un script o un playbook para crear una red, para aprovisionar servidores físicos o virtuales, o para realizar diferentes procesos de TI de los que ya hemos hablado en posts anteriores. El código de los scripts, playbooks y documentación son almacenados en un sistema de control de versiones, por ejemplo en Git. Esto permite tener diferentes versiones de las configuraciones de nuestra infra, ver la diferencia entre una versión y otra, revertir el despliegue de una versión a otra previa, y muchos otros beneficios de los que estaremos hablando en estos articulos.
Bien, pues lo primero que empece a poner en práctica fue el uso de ansible y git para gestionar las configuraciones de mi propio laptop con Kubuntu, la cual es una distribución GNU/Linux basada en Ubuntu pero con KDE, así que empece a escribir playbooks de ansible para realizar tareas como:
Personalizar el ambiente del shell
Configuración de repositorios de paquetes dpkg.
Instalación de paquetes dpkg.
Creación de usuarios y grupos.
Gestión de contraseñas de usuarios.
Actualización de paquetes.
En este proyecto he puesto algunos shell scripts para instalar ansible y sus dependencias en un sistema basado en ubuntu desktop. Empecemos descargando el proyecto desde gitlab:
$ mkdir ~/data/vcs
$ cd ~/data/vcs
$ git clone https://gitlab.com/jorge.medina/ansible-my-kubuntu-desktop
$ cd ansible-my-kubuntu-desktop
Ahora veamos el contenido del script que ejecutaremos para instalar ansible:
$ vim bin/install-ansible-on-ubuntu.sh
Veamos que contiene:

Hagamos correr el script:
$ bash bin/install-ansible-on-ubuntu.sh
Incluso comprueba la instalación.
Una vez que ya está ansible instalado en mi equipo, veamos que código de ansible inclui. Primero empece a escribir un playbook principal. Este playbook tiene instrucciones para ejecutarse en mi equipo local, es decir, localhost, usando el método de conexión local, me conecto usando el usuario jmedina, uso el método become para usar sudo y elevar los privilegios en tareas que requieran privilegios de root y ejecuto una tarea previa, que es actualizar el cache de apt. Después ejecuto diferentes tareas definidas en diferentes roles. Esto se ve así:
$ vim localsystem.ym

Como se puede ver tengo roles para diferentes grupos de tareas. Algunas son comunes a todo sistema que uso, sea físico o virtual, luego la gestión de paquetes, de shell, de almacenamiento y otras tareas relacionadas a herramientas de escritorio.
Los roles son una estructura de archivos y directorios para agrupar tareas realacionas a un mismo tema, lo cual permite la reutilización y distribución de código de infraestructura. Veamos la estructura de un rol, por ejemplo el common:

Esta estructura tiene varios directorios, expliquemos cada uno:
defaults: Aquí se definen variables predefinidas del rol, estas tienen la menor prioridad.
files: Aquí se copian archivos que queramos copiar al sistema a administrar.
handlers: Tareas que se ejecutan cuando se define una condición previa.
meta: Meta datos sobre el rol, esto es para mejor clasificación y documentación.
tasks: Tareas a ejecutar en el rol.
templates: Plantillas en formato jinja2 que se instalan en el sistema.
vars: Variables de el rol, estas tienen mayor prioridad que defaults.
Dentro de cada directorio por mínimo se espera un archivo y debe ser nombrado main.yml. Veamos el archivo main de tasks:

Los archivos main.yml se escriben en formato YAML, y siempre debemos empezarlos con 3 guiones seguidos (---). En el tasks empezamos un bloque con la sentencia name que describe la tarea a realizar: es como un comentario pero mejorado. En la siguiente línea se indica el módulo a usar, aqui ocupamos los siguientes:
command: Módulo usado para ejecutar un comando de shell de forma literal.
file: Nos Sirve para crear, modificar atributos, eliminar o hacer vinculos de archivos y directorios.
copy: Lo usamos para copiar archivos que se encuentren en el directorio file, se usan parámetros para definir el dueño, grupo, permisos y otras operaciones sobre el fichero.
template: Lo usamos para instalar una plantilla en formato jinja2. Estos están almacenados en el directorio templates con terminación .j2 y al momento de instalar la plantilla lo hace sustituyendo los valores de las variables por los datos que se pasen en defaults, var, o en tiempo de ejecución (en ese orden de prioridad de menor a mayor).
Como mencione antes, al momento de hacer correr un playbook (en la jerga de ansible se le conoce como un play) se pueden dar nuevos valores a las variables que existan en tareas y templates, ademas de opciones de la forma en que ansible "tomara control" del sistema. Si nuestro usuario necesita de contraseña para elevar privilegios, debemos de activar dos opciones al hacer la ejecución:
$ ansible-playbook localsystem.yml -k -K
-k Hara que el play te solicite la contraseña de login y -K preguntara por la contraseña para sudo.
Y listo, es todo lo que necesito hacer para comenzar a trabajar cuando dispongo de un nuevo sistema.
Para acceder al código del proyecto ir al URL https://gitlab.com/jorge.medina/ansible-my-kubuntu-desktop.
En los próximos articulos hablaré de como he usado ansible para la administración de servidores con GNU/Linux, tanto para uso personal como profesional. Si les gusta este articulo compartanlo con amigos que se puedan beneficiar de estos tips. Cualquier duda no duden en contactarme.
Gestión de Configuraciónes en Linux